1st Place Solutions for OpenImage2019 - Object Detection and Instance Segmentation
1st Place Solutions for OpenImage2019 - Object Detection and Instance Segmentation
作者:Yu Liu, Guanglu Song, Yuhang Zang, Yan Gao, Enze Xie, Junjie Yan, Chen Change Loy, Xiaogang Wang 机构:The Chinese University of Hong Kong, SenseTime Research
这篇论文更多的是技术报告,里面提到的思想之前的方法都已经有所体现。不过作为第一名的技术报告,还是值得仔细分析的。
在这篇文章中作者出发点是目标检测框架中分类的回归任务对于特征的要求不同。然后提出了Adj-NMS来代替soft-nms。最后给出了一些训练测试策略来提升最终效果。
这里我摘抄一下大佬的分析:分类任务希望无论目标的位置和形状怎么变化,什么类别的目标就是什么类别,即需要保证平移和尺度的不变性。回归需要保证目标的位置和形状变化反映在特征上,进而回归得到位置,即平移和尺度的相等性。来源:http://bbs.cvmart.net/topics/1661
简单的来说,对于分类任务而言,我们要求特征是对空间位置不敏感的,一个简单的例子我们无论给的是牛身体的某一个部分或者是全体都希望能分类为牛。而对于回归任务就不同了,如果给的是整体我们希望能收缩anchor,使其更紧密,如果是部分我们则希望扩充anchor,而且不同的部分扩充的方向不尽相同,这也就是说我们需要特征对空间位置是敏感的。
这里再补充一下相等性。这个概念其实是和卷积一致的,卷积的滑动窗口所具备的性质就是平移相等性。
Datasets
使用的是:OpenImages Challenge 2019 Object Detection,这个数据集是OpenImages V5 dataset的子集,一共1.74M图片,14.6M bounding box,500类,包含不同的级别。因为是分级的类别,包含父类和子类关系,测试的时候扩展了父类的标签(雾),作者使用了整个OpenImages V5的图像级标注和分割标注用来数据增强和弱监督。我们还使用COCO和Object365为重叠类别训练一些专家模型。
Decoupling Head
Decoupling Head利用传统的ROI Pooling主干预测anchor的粗略位置,然后用deform conv的方式校正分类分支。再在主干上保留原始的回归和分类任务。总而言之可以将其概括为:Double Head RCNN + AlignDet(或GA-RPN) + Faster RCNN
Decoupling Head从名字上来看就知道是为了解决目标检测框架中分类的回归任务对于特征的要求不同这个问题而存在的,正常的Faster RCNN框架,这两个特征是耦合在一起的,只在预测阶段使用不同的FC层来转换特征,这是远远不够的。
首先作者介绍了一下相关的研究工作,第一个研究类似问题的工作是IoU-Net,他们发现产生良好分类分数的特征总是预测一个粗糙的边界框。为了解决这个问题,他们首先引入一个额外的头部来预测IoU作为定位置信度,然后将定位置信度和分类置信度相加作为最终的分类得分。这种方法确实减少了偏差问题,但以一种折衷的方式——其背后的基本理念是相对提高一个紧边界框的置信度得分,并降低一个差边界框的得分。在每个空间点上仍然存在偏差。
我们关注IoU-Net已经很久了,不过我们的看法是,回归效果好的框的置信度并不总是得分是最高的,所以IoU-Net试图给回归好的框重新打一个分,解决简单的分类任务置信度不能代表回归结果好坏的问题。这看起来是对一个问题不同方面的分析,不过遗憾的是我们并没有试图从特征层面来解决这个问题,而是借鉴了IoUNet的方法付试图从引入一个额外的score方式来解决这个问题。一个典型的类似的方法就是mask scoring cnn。
沿着这一方向,Double-Head R-CNN被提出将姊妹头分支重新划分为两个特定的分支进行分类和定位。尽管每个分支都经过了精心的设计,但通过添加一个新的分支可以认为是对信息的分离,实质上减少了两个任务的共享参数。虽然这种检测头的分离可以获得令人满意的性能,但是由于输入到两个分支的特征是由同一个方案的RoI Pooling产生的,因此这两个任务之间的冲突仍然存在。
可以看到,旷视的Double-Head R-CNN应该是第一个明确的将这个问题摆到明面上的论文了,值得一提的是Double-Head R-CNN当时也拿到了coco比赛的第一名。下面放一个结构图:
可以看到,大体上这篇论文的思路是在Double-Head R-CNN更近了一步,换句话来说他没有考虑到anchor与特征的对齐关系。anchor与特征对齐的研究也有很久的历史了,包括RefineDet,Reppoints,Guided Anchoring,AlignDet。一个简单的解释是,不同的anchor具有不同的形状,而在特征图上他们对应着同一个区域(或者点)的特征,这是不合理的。
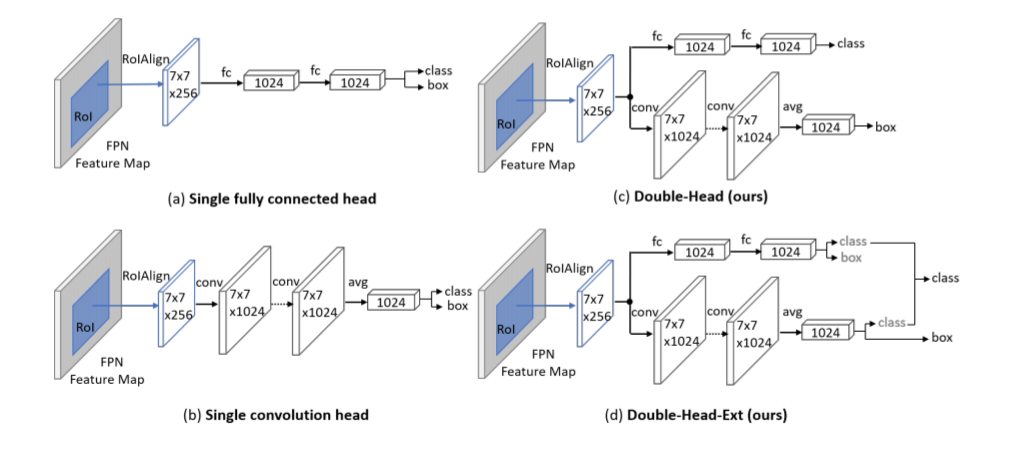
最后作者解释了一下他们想法的来源:这是受到自然洞察力的启发,例如,某些显著区域的特征可能具有丰富的分类信息,而这些边界周围的特征可能擅长边界盒回归。
Detail description
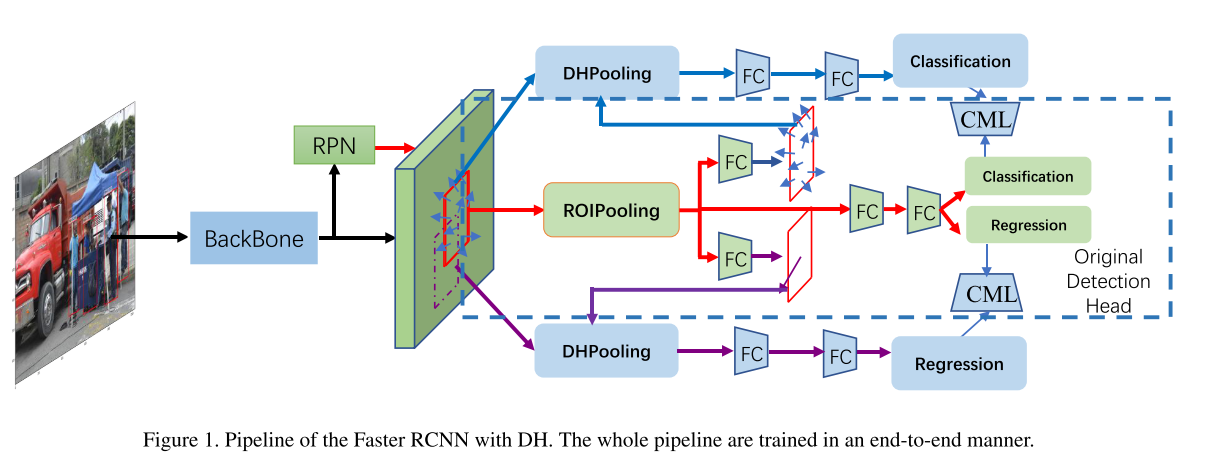
如图1所示,与Faster RCNN中的原始检测头不同,在DH中,我们通过自学习的逐像素偏移和全局偏移来分离分类和回归。DH的目的是寻找分类和回归的最佳特征提取。此外,为了便于DH的学习,我们提出了可控边际损失(CML)来推动整个学习。
首先作者通过两个FC来学习分类回归任务的特征偏移: 其中F表示RoI Pooling的特征,$\theta$表示FC的参数。DHPooling是一个带offset的ave pooling过程。具体计算公式如下: X表示输入特征图,n表示roipooling bin中点的数量,$p_0$表示bin中最上角的点,可以看到,拿掉C就是一个avepooling,对于回归的公式完全一样这里就不列了。CML的定义如下: $S_o$是原始box head里面的分数,$S$是DH投中的分类分数。$|\cdot|_+$和relu一样,$m_c$是一个预设的阈值,回归分支的含义同理,这里$m_c,m_r$设置为0.2
可以看到作者这里设计的思路是:DH分支中预测的S以及IoU应该更准确,$S,IoU$相比$S_o, IoU_o$太小时需要产生loss来使得他们预测正确。应该是一个加速收敛的loss。
Adj-NMS
Adj-NMS是NMS和soft-NMS的结合,这一部分作者说的比较模糊,应该是先进行一个阈值为0.5的NMS,然后采用一个rescore函数为$w=e^{-\frac{I o U^{2}}{\sigma}}$的soft-NMS。这里作者说$\theta$设置为0.5。
一开始我还以为是什么nb操作···不过这里这个方法其实有丶东西,soft-NMS取代NMS的思路是不完全抑制IOU很大的情况因为考虑到框可能很密集,而overlap越高的情况下得分其实是越低的,这时使用NMS完全没有什么问题,这也就意味着NMS可能确实和softNMS是可以在某种程度上互补的,这和我们目标的密集程度有关。假设当前框得分最高为1,那么经过NMS之后与他最大的IoU的框得分最多为$0.99\hat 9$,和其IoU最大为$0.49\hat 9$那么代入公式,他的得分会被抑制到0.606,比该框overlap还大的框得分会小于0.606,我们需要判断的就是小于0.606置信度的框对ap到底是有利的还是有害的。
Model Ensemble
Naive Ensemble
模型集成作者采用了PFDet中的方法和常用的投票策略,给定bounding boxes(P),以及topk个与之IOU较高的候选框,首先依据验证集的分数用PFDet中的方法来分配各个模型在集成时的权重,然后进行第二次加权:
$$
C=S_{\mathcal{P}}+0.05 * \sum_{i=1}^{k} S_{P_{i}}
B=0.7 * B_{\mathcal{P}}+\frac{0.3}{k} * \sum_{i=1}^{k} B_{P_{i}}
$$ k设置为4,
PFDet中的方法我不清楚,这里第二次加权就是一个简单的投票过程,不过不是很懂为啥C可以超过1.
Auto Ensemble
作者使用不同的模型结构、数据集、类别划分策略、数据增强和监督训练了28个检测器。首先使用上面提到的朴素模型集合具有相似设置的检测器,从而将检测从28减少到11。然后我们设计并启动了一个自动集成方法,将它们合并为1。
可以看到,有钱真的可以为所欲为
这里作者将模型集成过程变换为二叉树生成过程。所有父节点都是其子节点通过一组操作的集合,根节点将是最终的检测。在比赛中,作者采用两阶段的搜索过程:首先,作者为每个子节点搜索贡献相等的二叉树结构;然后,作者基于固定树搜索父节点的算子。
这一部分太简略了,完全不懂具体是怎么做的。可能是先搜索可能的节点结构,11个叶子节点所能生成的二叉树结构有?种,然后在遍历所有的父节点操作。这父节点操作可能需要离散化以减小搜索空间。
这里作者提到了autoEnsemble leads to 2.9%, 3.6% and 1.2%, 1.0% improvement on the two validation sets and ∼0.9% on the public lead-board compared to the Naive ensemble.
Bag of Tricks for Detector
这一部分应该是打比赛的关键了,当然上面的ensemble也很重要。
Sampling
首先是处理长尾数据的方法:采样
确保500个类别的目标中各个类别被选取的概率相等。作者这里使用采样和不采样的差距有5.76个点。
采样对于长尾分布数据还是非常有效的,没有采样甚至可能无法收敛,这里应该是过采样策略。
Decoupling Backbone
对于第25~28个模型,在特征步长为8的特征图上采取Decouple Head的策略,一个分支专注于分类任务,其中回归被赋予较低的权重,而另一个分支则相反。
Elaborate Augmentation
由512个加速器训练的模型中采取full class batch和elaborate augmentation策略,full class batch表示每个batch中每个分类的样本至少一个,elaborate augmentation随机选择一个类别,利用旋转放缩裁剪等方式进行数据增强
我不是很理解这么做的用意,这里选了一段别人的理解:这样可以使得一幅图中的类别数变少,缓解数据不平衡问题。不过看了这个说法我还是不懂甚至怀疑他说的有问题。
Expert Model
专家模型是指在数据集的一个子集上训练检测器来预测类别的一个子集。其动机是,一般模型很难在所有类中都表现良好,因此我们需要为专家模型选择一些类别,以便专门处理
专家模型有两个重要因素需要考虑:the selection of positive and negative categories, and the ratio between the positive and negative categories. 其中the selection of positive and negative categories需要考虑到类别之间的混淆。作者从分级类别、混淆矩阵和视觉相似度三个角度来定义易混淆的类别。然后设计了专家模型的训练方式:
1.选择初始类别$C_{pos}$,例如验证集map的最低十个类别。将包含$C_{pos}$的图像添加到positive数据子集$\chi_{pos}$。
2.使用余弦矩阵添加混乱的类别。对于满足$dist(c_i,c_j)>thr,c_j⊆C_{pos}$要求的每一类$c_i$,将其添加到$C_{neg}$中。$thr$等于0.25,以确保正负数据的比率接近1:3。将含有$C_{neg}$的图像添加到阴性数据集$\chi_{neg}$。
3.训练一个带有$\chi_{pos+neg}$的检测器来预测$C_{pos}$的种类。
该检测器在推理阶段,每个RoI都有一个对应的分类分数,shape为($C_{pos}+1$)。如果背景分类得分大于所有其他前景得分,则此RoI将不会进行回归。这种修改可以减少很多不必要的假阳性样例。
这个专家模型应该效果非常好,设计思路也很有效。打比赛的时候应该可以借鉴。不过对于文本检测可能没有作用。
Anchor Selecting
we have 18 anchor(ratio:0.1, 0.5, 1, 2, 4, 8. scale:8, 11, 14)
Cascade RCNN
这一部分没啥好说的,迭代回归就是强。
Weakly Supervised Training
同样是处理长尾问题,这里采用弱监督加入额外的训练数据
具体来说是集成弱监督检测器WSDDN和全监督检测器Faster-RCNN,然后通过端到端训练的模式来同步提升两个检测器的性能,当遇到有包围盒的数据时,利用它训练全监督检测器,约束弱监督检测器。在遇到图像分类级数据时,利用它来训练弱监督检测器,并从弱监督结果中挖掘伪真值来训练全监督检测器。
这里我不理解的是faster rcnn是不是应该对应最终的模型,还是说重要的是挖掘出来的伪gt标注。不过这种方式也是有效的。可以借鉴用来做LSVT。
Relationships Between Categories
OpenImage数据集中的类别之间有一些特殊的关系。例如,有些类总是与其他类一起出现,比如Person和Guitar。在训练集中,90.7%的图像中出现了有吉他的人。所以当检测到一个置信度很高的吉他包围盒,并且有一个置信度较高高的人包围盒时,我们可以提高这个人包围盒的置信度。
这里作者使用条件概率来计算上面提到的co-occurrence relationship,此外作者还提到了surround relationship and being surrounded relationship。这些类别之间的特殊关系可以作为提高或降低某些包围盒可信度的证据,从而提高检测性能。
感觉这种方式实际操作没有这么简单,作者直接设计启发式规则来完成语义信息的融合,其实如果能想办法把这种信息编码到网络中应该是不错的一个思路。
Data Understanding
作者发现OpenImage数据集中对于特定类别的目标标注有歧义,比如火炬和手电筒,剑和匕首等,所以作者将有歧义的类别细分成了上面说的多类。同时作者也发现有些目标,比如葡萄缺乏个体检测框等,作者就利用葡萄串的实例标注,扩展了很多葡萄框。
Implementation Details
13/26 epochs with batch size 2N @ N accelerators, where ’N’s are in range of [32, 512] for different models based on the available number of accelerators.
这里加速器大概就是GPU等东西了,512块GPU是真的无情。
在推理阶段,对于验证集,我们直接生成结果,对于测试集,我们采用[600、800、1000、1333、1666、2000]的多尺度测试,最后的参数是通过对第[9,13]个epoch的参数进行平均(对于第2x scheduler,则为[19,26])来生成的。基本的检测框架是FPN[18]和Faster RCNN,并使用class-aware sampling。
这里有个操作时对多个epoch的ckpt参数进行平均,这是我之前没见过的新操作,不知道有没有很好的借鉴意义。class-aware sampling应该指的是第一个trick吧。
Results of Object Detection
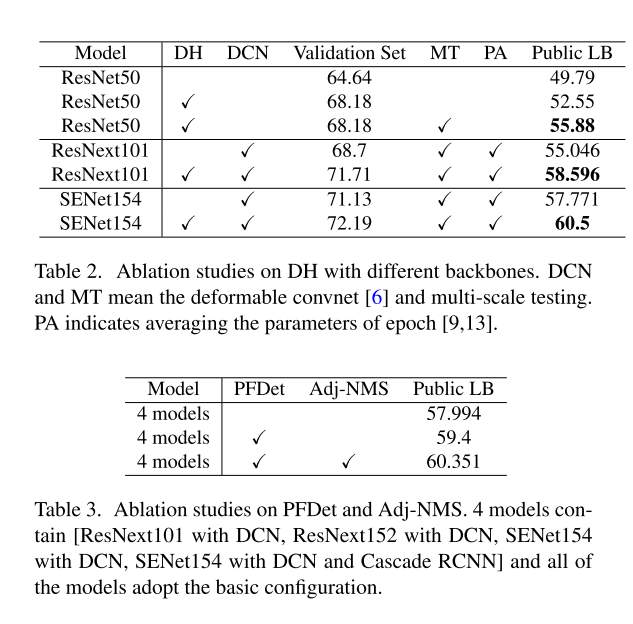

这个结果我看呆了,模型集成和backbone真的是比赛第一生产力。
后面还有分割的结果,以及配套的方法,这里就不放了,有需要可以看一下。
这篇技术报告虽然在方法上没有很大的创新,因为方法方面会总结到论文Revisiting the sibling head in object detector里面,并且和Double Head RCNN + AlignDet(或GA-RPN) + Faster RCNN确实很类似。不过这样他确实比较好的解决了分类和回归不应该使用同一个特征的问题,起码比Double Head RCNN多考虑了特征对齐的问题。
不过从实用包括比赛的角度来看,这篇论文的价值还是非常高的。从上面的结果我们可以看到,巧妙的结构设计虽然能够帮助我们提升网络的效果,但是并没有达到饱和的程度,更加复杂有效的backbone以及模型集成方法依旧是提升我们效果的根本手段。
这里也就引申出另外一个问题,到底依靠一个检测器完成所有检测任务是否是可行的,因为这篇报告中使用专家模型包括模型集成所带来的提升确实太大了。如果从人类的能力来看这确实是可行的,那么为什么我们训练的深度检测器效果和速度都无法令人满意呢?
SwapText: Image Based Texts Transfer in Scenes
SwapText: Image Based Texts Transfer in Scenes
DGST : Discriminator Guided Scene Text detector
DGST : Discriminator Guided Scene Text detector
作者:Jinyuan Zhao · Yanna Wang · Baihua Xiao · Cunzhao Shi · Fuxi Jia · Chunheng Wang 机构:自动化研究所
这篇文章从题目来看给人的感觉是挺不错的,目前来说GAN一般用来做图片到图片的生成包括擦除风格迁移等等,当然换个思路来说,既然能够生成,甚至是能够擦除文本,那么用来做检测也是完全没有问题的。
后来去查了一下,发现是自己孤陋寡闻了,gan用来做语义分割历史也有挺久的了,GAN在image to image translation, semantic segmentation, image style transfer方面都有很好的应用,本质上还是图片到图片不过给图片赋予了不同含义
第一个用gan来做语义分割的应该是这篇Semantic Segmentation using Adversarial Networks
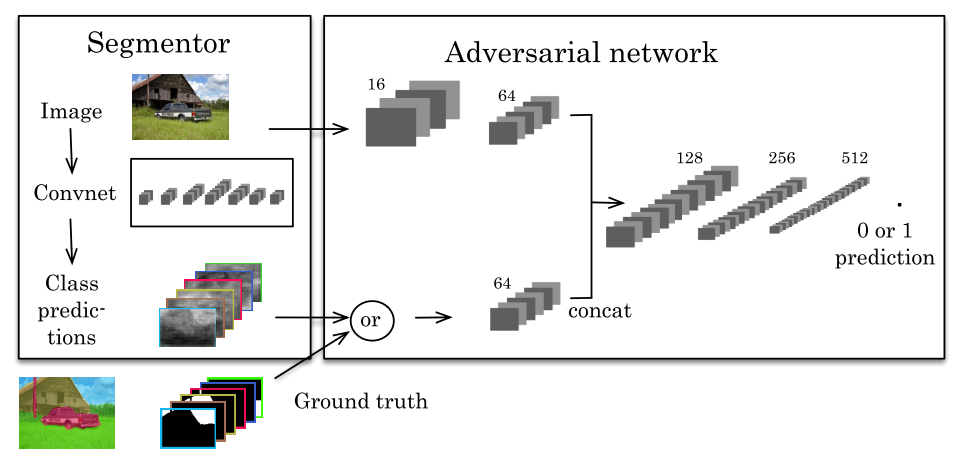
近年来,许多研究者将语义分割方法引入到场景文本检测中,取得了很好的效果。为了提高场景文本检测的分割效果,本文提出了一种基于条件生成对抗网络的检测框架DGST(Discriminator Guided scene text detector)。与现有的基于语义分割的方法生成的二值文本分数图不同,本文提出了一种多尺度、多信息的soft文本分数图,以更合理地表示文本位置,解决了文本提取过程中的文本像素粘连问题。
可以看到作者主要想解决的问题是分割方法的像素粘连问题,这也是分割的老问题了。另外一个贡献点是多尺度分割图,虽然目前的分割大多直接融合多尺度特征,不过我觉得也应该有多个特征图上预测分割结果的论文
Introduction
现有的场景文本检测框架主要受到一般目标检测方法和语义分割方法的启发。基于一般目标检测的方法通常分为两个阶段:RPN网络提取候选文本区域,分类网络对RPN网络中的特征进行分类,得到最终的文本位置。语义分割的方法认为文本是一个特殊的语义实例直接将文本从背景中分离出来,这种方法被称为一阶段方法,与两阶段方法相比,一阶段方法更直观、简洁,但仍存在以下问题:
不精确分割标签:标注区域存在大量的背景像素,当以文本像素为目标进行像素级实例分割时,这些背景像素可能会造成学习混乱,降低训练效果。
多任务学习问题:一些经典的单阶段方法,如EAST[35]采用从同一卷积网络中获取文本得分图和回归任务所需特征的策略。然而,回归信息作为一种距离测度,不能很好地与基于图特征的文本评分图共享CNN网络提取的特征,其性能略弱于两级检测器。
这里作者主要做的是分割,所以着重分析了分割的问题。第一个是不精确的分割标签,这一点其实是很有道理,我们很早也讨论过是否有必要对文本区域逐像素的进行标注,因为目标检测就是这么干的,而对于文本来说,逐像素的标注成本过于高昂导致没什么人这么做,希望作者能对这个问题有自己的解决方法。不过这里我有一个地方不太认同,作者认为这种多任务学习(回归和文本得分)不能很好得增强效果是一阶段性能没有二阶段好的原因。首先多任务学习大家普遍认为都是带来提升的,硬要说回归和分类特征不太好认为是多任务也不是全无道理,不过二阶段方法也是这么多任务的。
贡献:
- We introduce the framework of generative adversarial networks into the task of scene text detection and design a suitable structure for it.
- We redefine the representation of text area and non-text area in the framework of semantic segmentation, and solve the learning confusion caused by back- ground pixels.
- Extensive experiments demonstrate the state-of-the-art performance of the proposed method on several benchmark datasets.
Related Works
作者首先介绍了基于通用目标检测框架的检测方法,这些文本检测器将单词或文本行作为一个特殊的对象,并添加后续的分类符来过滤卷积特征中的文本区域。通常,这些方法需要添加NMS来获得最终的文本位置。
然后作者介绍了基于语义分割的方法,这里作者着重强调了PixelLink,PSENet和Textfield
最后作者介绍了GAN相关的方法,主要是GAN,CGAN,CycleGAN以及他们的变体。
在上述方法的启发下,本文采用生成性对抗网络框架,设计了更合理的软文本评分图,以获得更准确的语义分割结果,并用连通成分分析代替传统的NMS过程。这不仅避免了标签不精确造成的学习融合,而且使整个网络训练过程成为一个单一的任务学习过程,更加简洁直观。
这里比较遗憾,我以为他代替NMS过程是什么新的东西,然而分割方法本身都不用nms
METHODOLOGY
图2示出了所提出的场景文本检测方法的流程图,该方法是一个单阶段检测器。在训练过程中,生成器和判别器交替学习,使生成器最终将输入的场景图像转换成相应的soft文本分数图。这消除了中间步骤,例如候选方案、阈值和预测几何形状的NMS。后处理部分只包括联通成分分析。
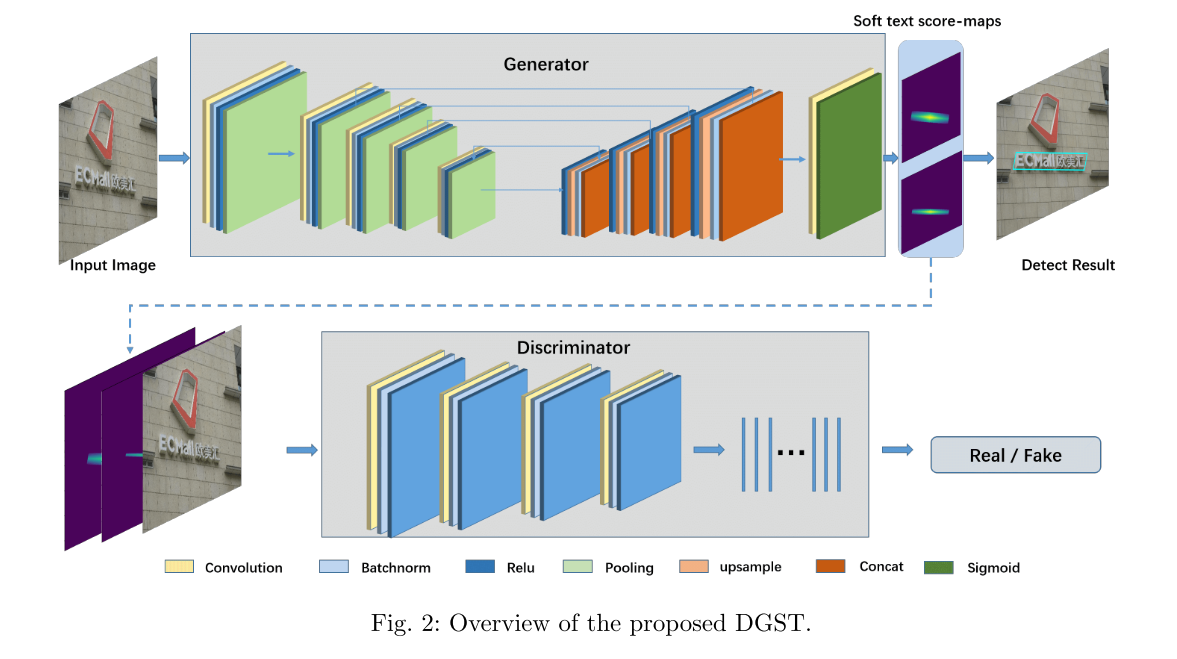
Label Generation:针对不精确分割标签的问题,其中一些方法试图更紧密地缩小(shrink)注释框以减少背景像素,如图3(a)所示。然而,这样的刚性收缩并不能准确地调整每个文本框的标签,并且文本边缘和背景像素也不能很好地区分,这使得最终的文本框位置偏离了预期的结果。CRAFT将文本行注释分为单个字符注释结果,通过测量每个字符上的高斯距离得到文本得分图,进一步减弱了背景噪声对文本特征提取的影响,但从字级注释到字符级注释的转换带来了额外的复杂工作。本文提出了一种基于标注框中像素与相应边界之间的距离对生成文本分数图的方法。在水平和垂直方向上比较标注框中的像素与相应边界之间的距离,突出显示文本行的中心位置,并弱化容易与背景混淆的边缘上像素的权重。

可以看到这里也没有什么特别的变化,效果甚至不一定比高斯好,看后面有没有相关的实验。这里依旧没有提到我们之前关注的逐像素的语义标签对文本检测是否有帮助。
标签的计算公式如下: Network Design:
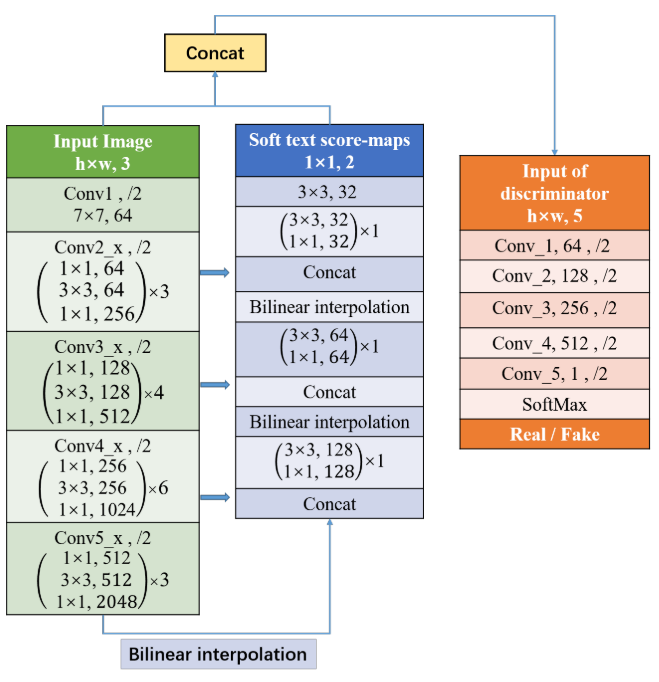
生成器就是一个简单的res50+UNet,这里使用双线性差值来进行上采样。和east很接近。可以看到判别器是一个全卷积网络,是一个简单的二分类分类器。
生成器的训练没啥好说的就是一个分割,判别器的训练:
Combining the original picture with the corresponding text score maps of different shrink factors as the input of the discriminator, the discriminator determines whether the input text score map is a labeled ground truth image or an imitation of the discriminator.
可以看到这里的训练模式在图2说的不是很明白,倒是和第一张图是一样的。
LOSS:两个损失函数如下所示: 其中第一项是CGAN的通用公式,第二项是作者用来训练text score map(生成器)的loss,是一个L2loss
Text boxes extraction :
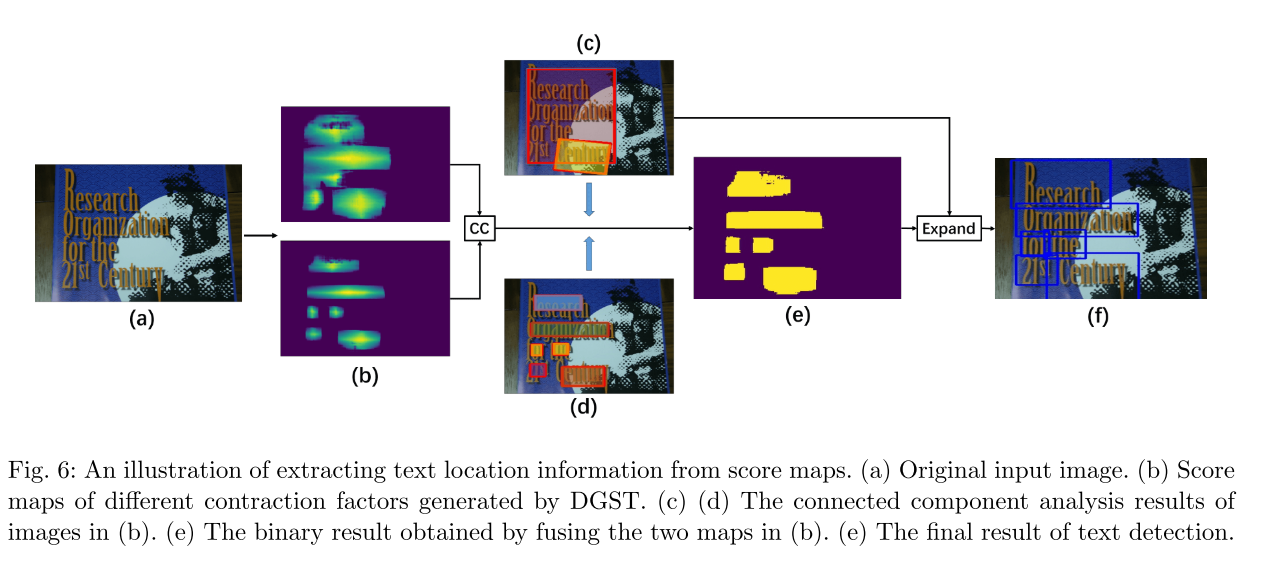
分割方法无可避免的就是后处理,这篇文章的后处理也很复杂,从生成器中获得两个具有不同收缩因子的文本分数图,通过直接分析图6(b)中分数图的连接成分,可以得到图6(c)和图6(d)中相应的文本框。可见,非收缩分数图存在内聚问题,收缩分数图能较好地提取文本框间距信息,但会丢失一些文本信息。
这一步骤类似PSENet的做法
因此,我们将生成器中的两个分数图组合起来得到一个更完整的图像,如图6(e)所示,并在图6(c)中文本框的约束下展开图4(e)中的文本框,以便边缘可以完全包围整个文本区域。最终文本框位置如图6(f)所示。算法1显示了更具体的过程:
EXPERIMENTS
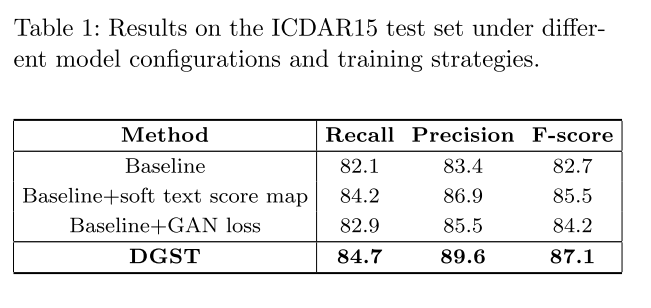
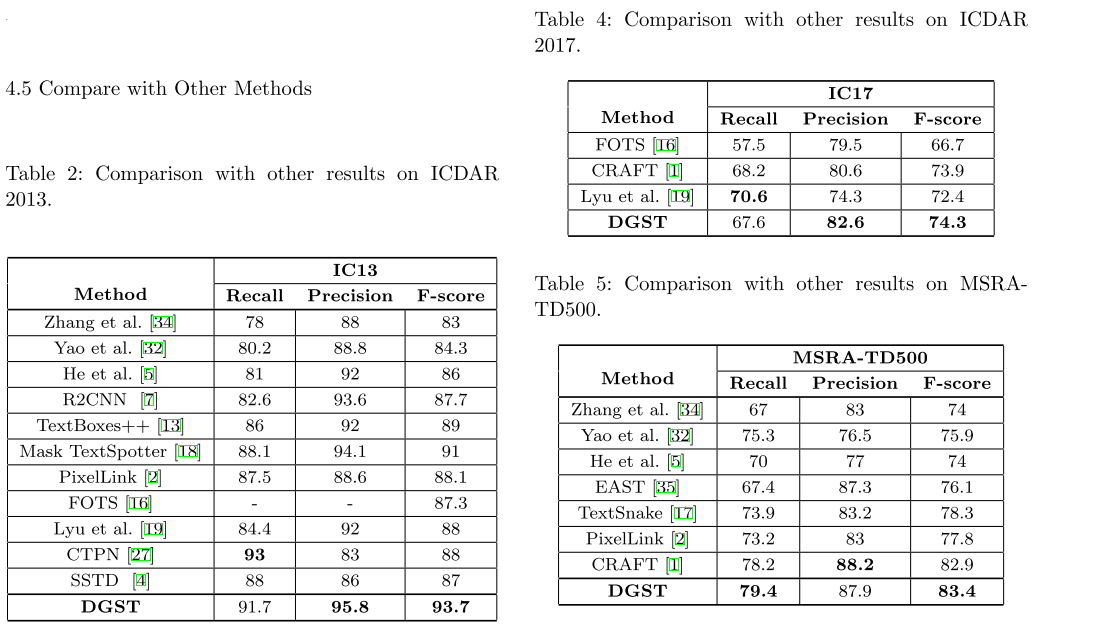
总的来说,这篇论文没有特别出彩的地方,有点将16年的Semantic Segmentation using Adversarial Networks结合PSENet直接迁移到文本检测领域的味道,不过使用GAN来做检测,特别是用discriminator来给我们的检测器提供一个额外的监督是一个可以尝试的做法,毕竟他在测试的时候可以不用引入已提供额外的计算,在训练的时候反而能够用多任务的形式给我们的检测器带来额外的矫正。和端到端中识别器矫正文本检测结果有异曲同工之妙。
Paper_reading
Text Perceptron: Towards End-to-End Arbitrary-Shaped Text Spotting
作者:Liang Qiao, Sanli Tang, Zhanzhan Cheng, Yunlu Xu, Yi Niu, Shiliang Pu, Fei Wu
机构:Hikvision Research Institute, China; Zhejiang University, China
上一次end2end比较活跃还是19年的iccv,当时有三篇论文,一篇google的Towards Unconstrained End-to-End Text Spotting,一篇自动化所的textdragon,一篇阿德莱德的Convolutional Character Networks。这一次aaai又出了两篇end2end的论文。
检测里面有很多处理不规则文本的方法,但是它们对识别模块适应性不好,原因有两点:1.识别曲线文本效果不好。2.检测识别分开使得整个系统的结果是次优的。为了解决这两个问题,本文提出了Text Perceptron解决上面的问题。首先是分割,然后Shape Transform Module用控制点解决矫正问题,然后送入识别。在13、15、ctw1500、total上做了实验。
end2end方法的动机好像没有特别大的创新,不是非端到端效果不好,就是检测和识别不匹配。
这里看到主要流程是分割,矫正和识别,流程和fots区别不大,检测换成了分割,roi rotate 换成了tps
Introduction
检测结果已经取得了很大的进展,但是对于识别仍然有没解决问题:检测个识别的输入是bounding box,一般来说是一个水平矩形,对于不规则的文本就要求识别部分需要校正的能力。这种策略会从两个方面降低系统的性能:1.额外的矫正模块需要在识别网络中设计。这种矫正方法很难在无标注的情况下学习,同时会带来额外的计算代价(大雾)。2.这种流程不是端到端的,于是效果不好,这是因为识别模块的loss不能传到检测模块。
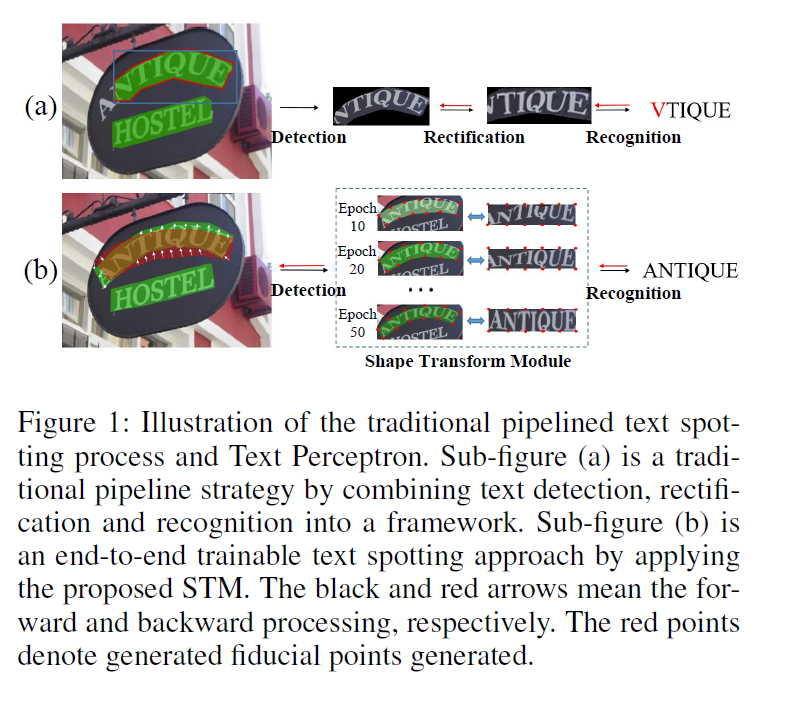
最近有两个端到端的方法,mask textspotter使用maskrcnn逐字符检测不规则文本。但是这个方法丢失了字符之间的语义信息,同时需要字符标注进行端到端的训练。TextNet使用透视变换roi pooling来处理不规则文本,他无法处理曲线文本。
intorduction里面也是老生常谈的内容,作者这里对比了两个典型的end2end方法,不过看起来和以fots为代表的那套 检测-变换-识别的套路没有区别,唯一的改变是之前都是在改roi pooling,现在开始玩控制点了。
这一段看起来更像是relation works,不过他这里提到了TextNet是accv18仿照fots做的一个透视变换roi pooling,我当时还想复现这个东西来着,不过水平不够,速度太慢。但是看到觉得accv里面还是有一些蛮有意思的论文的
这些限制让作者寻找新的方法来解决,一个比较有意思的方法是TPS,但是STN来学TPS不好,他直接用crop rectangle来隐式的学习控制点,这样学习很困难。于是作者使用了一个新的思路来学习这些控制点,同时利用识别的损失来修正这些控制点。STM就负责来做这件事。它连接了检测和识别两个模块,解决了检测识别的不兼容问题。
Text Perceptron的主要构成如下:1.作者使用了一个分割模块来检测文本,他负责检测文本的文本区域的四个子区域:起点、终点、上、下,可以分开文本,同时可以确定阅读顺序。2.STM产生控制点并end2end的优化它,解决了检测识别不匹配的问题。3.一个序列识别模块
上下左右逇思路很早就有了,该分割目标可以看做pixel link 和text mountain的结合。不过值得注意的是,这里的上下是一起预测的,被称为boundary,起始终止的思路也很早就有了,具体的记不太清,不过有一篇特别秀的Start, Follow, Read: End-to-End Full-Page Handwriting Recognition
STN包括控制点的思路最早是在aster引入文本识别的,他这里不引aster无可厚非,但是我相信他肯定是看了aster才产生的灵感,甚至这里不同STN来做TPS是想将该方法和aster区分开的一个设定,直到现在我还好奇他具体是怎么不用STN来做的。
本文的主要贡献如下:1.检测器能够确定识别顺序。2.STM实现了端到端。3.性能好
Related Work
检测部分主要介绍了anchor的分割的方法,anchor的就不说了,和本文关系不大,分割的方法主要介绍了east、pse、Textfield、Textsnake
这里east被分到分割的方法里面了。这里介绍的分割方法和他的都不相关,所以也没对比。不过text field和它还是有点类似的
端到端的方法,这里作者分了几个阶段,首先是检测+识别,以textbox++为代表,然后使用变换模块将检测识别连起来,以fots为代表,再然后解决任意形状的文本问题,以TextNet为代表,但是他们都不能解决任意方向文本问题。最后mask textspotter尝试解决这个问题但是需要字符标注,同时丢失了序列识别的语义特征。
很遗憾作者没有和任何一个ICCV2019的方法来比,他们都可以处理任意形状文本的识别,而且截稿之前其实都出来了,不过可能作者就是iccv2019没中然后中了aaai2020
Methodology
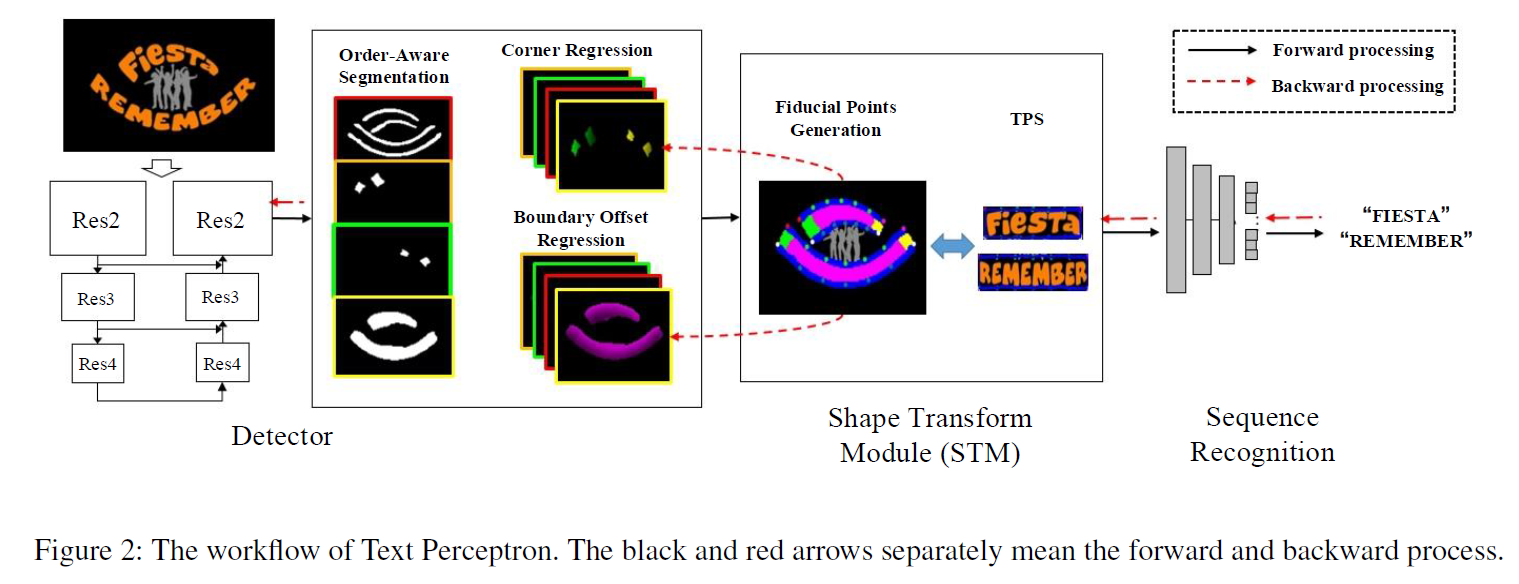
本方法的主要结构如上图所示:主要包括三部分:
检测部分主要包括resnet和fpn作为backbone,主要的分割任务为3个:包含阅读顺序的边界分类(4分类),角点回归和边界回归。
这里大概是借鉴了2阶段方法如faster rcnn或者是east的思想,加入回归来修正检测结果。这大概也就是east为什么被分到分割方法里面了吧,那这样其实faster rcnn anchor数量设为1也可以算分割方法,真是傻傻分不清。
STM迭代的在预测的分数图和集合热度图上产生控制点。然后利用TPS来矫正。
识别模块crnn和1d attention。
检测任务:检测模块第一个任务预测起始、终止、上下(boundary)、中心区域的点,主要看怎么生成gt。后面两个任务主要负责提高分割描述的准确度进行了二次回归。角点回归包含四个热度图,分类的对象是起始和终止区域的点,目标是他们到对应两个角点的x、y距离。边界回归任务同样四个热度图,分类的对象是中心区域的点上下左右四个方向到boundary的最近具体,具体可以见图3。计算loss的方法不是交叉熵,而是smooth l1。
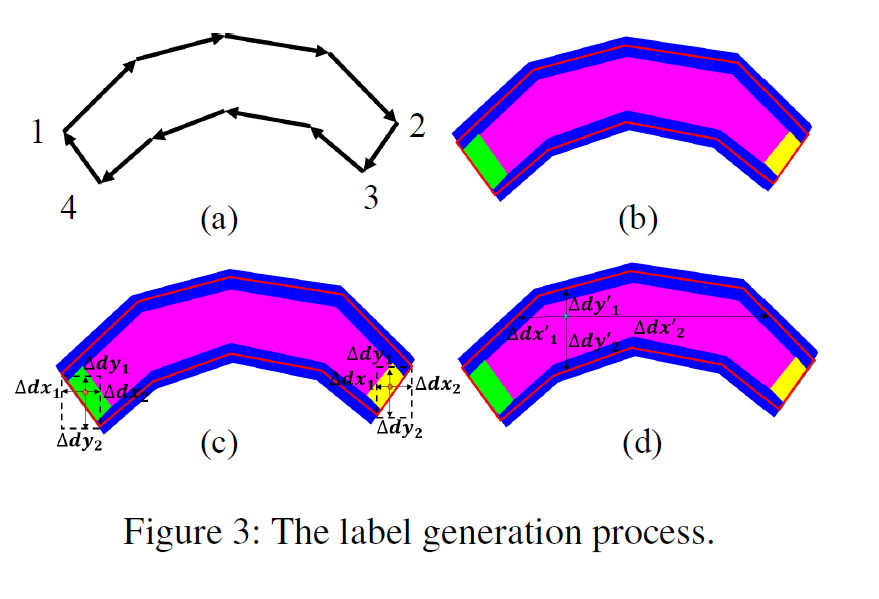
生成检测结果:根据上面的预测值,怎么得到最后的检测结果呢?将中心区域、上下左右依次画到图上,中心区域自然就会被边界分开,同样起始终止也会被边界分开,于是每个中心区域就能和一个起始终止匹配上,对于多个匹配选择面积最大的,对于没有匹配的则丢弃。
gt:如图3(a):1、4是head区域的2个角点,2、3是tail区域的2个脚垫。所有的数据集,1、4都是固定的,以为标注按照1为起点,顺时针来标的。对于ctw这种14个点的2、3也是固定的,对于2、3不固定的数据集,利用两个假设:1、其实和终止边是水平的,2.和tail边相邻的两个边夹角接近90°。来寻找2、3点。
对于四个区域的定义,利用了Wu and Natarajan 2017中的收缩和扩展思想,剩下的对着图其实可以看得很明白。
90°是textsnake提出来的假设,不是很懂为啥不完全按照text snake的来,有凑字数的嫌疑。同样,收缩方法也换了,个人觉得意义不是特别大。
集合回归gt的定义看图以及前面的说明就好了,很清楚直观,注意箭头的终点。
控制点生成:最重要的部分来了,输入分割图和上面回归的几何图,输出2xN个控制点。首先是4个角点,由对应区域的点和对应的偏差来计算他们的均值。一个例子,如图4,为了计算P1使用head区域(绿色)的点,计算如下: 总结来说就是计算一个均值,知识看起来很大而已。对于其他的关键点利用二分法得到。如图4,找到一对对应点,如P1,PN,那么计算他们的水平跨度(横坐标的差)和竖直跨度,水平跨度长则沿着他们的中点做竖直线与边界交于$p\lfloor(N+1)/2\rfloor$,它的横坐标为$x_{m i d}=\frac{\lceil(N-1) / 2\rceil}{N-1} \times P_{1, x}+\frac{\lfloor(N-1) / 2\rfloor}{N-1} \times P_{N, x}$,反之亦然。值得注意的是,这里的边界是中心区域和上面的回归结果得到的,首先作者定义了该点对应的环: $\Delta e p$是这个边界环的范围,是一个超参数。这个区域的点见图4中加深的红色区域。然后我们可以根据这个区域的点和回归值计算对应的y坐标: 这个公式看起来就更复杂了,其实本质是$y+\Delta dy$求平均,依旧是一个平均。

得到了控制点之后剩下的过程包括TPS以及梯度回传以及loss设置,没什么特别的贡献,这里就不详细说明了。
不过虽然没什么新的东西,但是确实进一步的强调了我的识别模块的loss就是可以通过TPS回传到检测模块,同时这种写公式的功底也值得我们去学习。
Experiments
实验就不多说了,看图即可,主要是13、15、total、ctw上的实验。
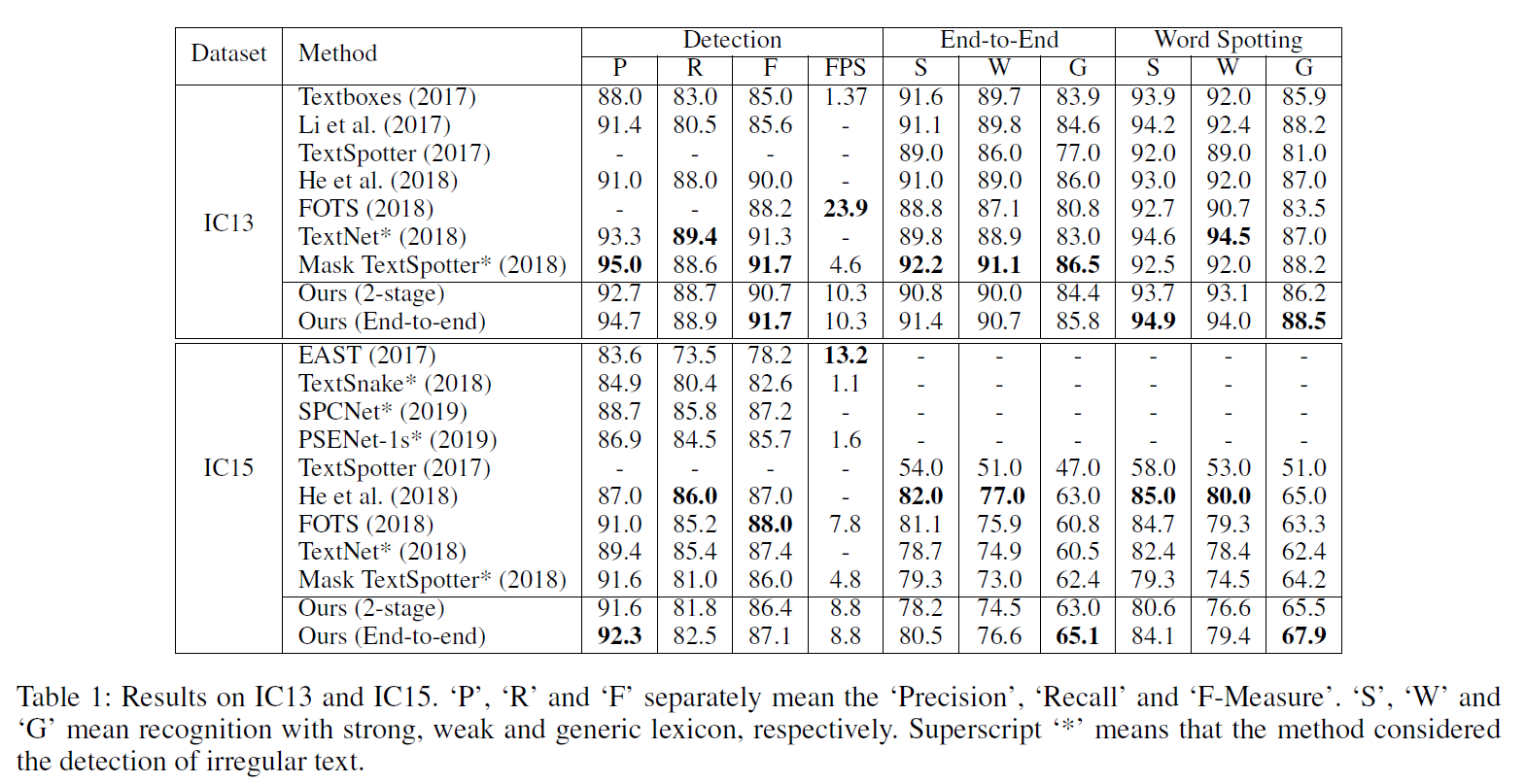
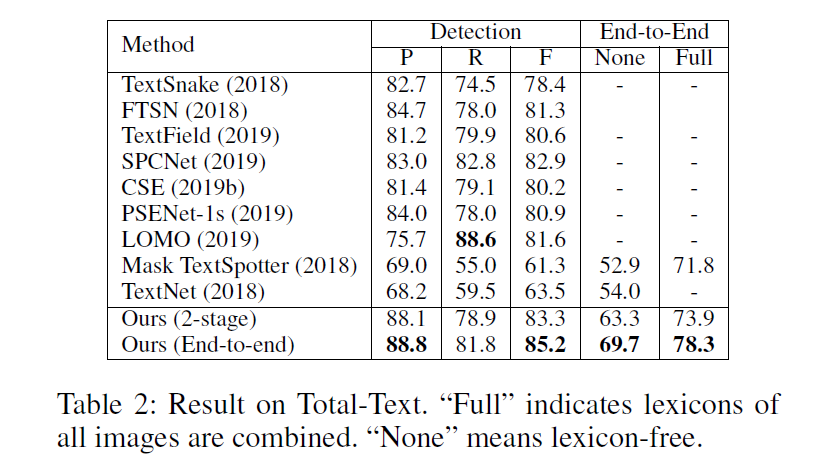
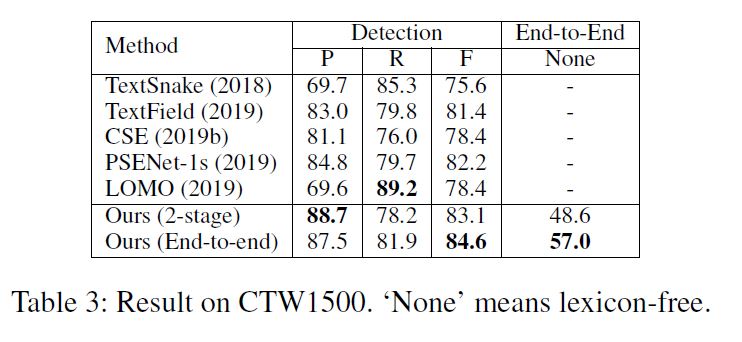
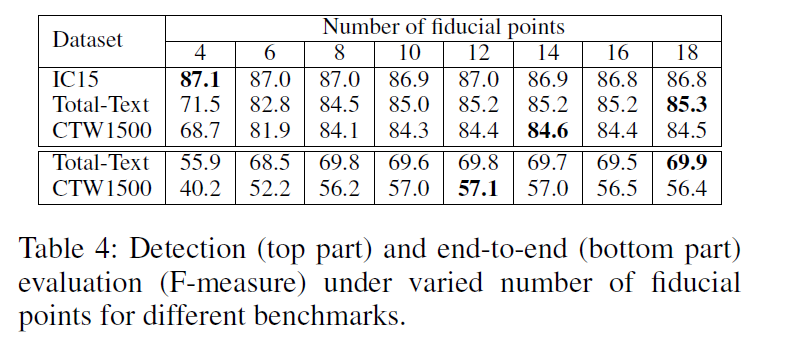
值得注意的是这里有一个关于控制点数量的ablation study。作者在这里的分析结果是对于常规数据集IC15来说,4个点就够了,多了没有啥变化,对于曲线来说,控制点的数量不应该少于10个,多了之后基本稳定。
Paper_reading
GTC: Guided Training of CTC Towards Efficient and Accurate Scene Text Recognition(AAAI2020)
Wenyang Hu,1 Xiaocong Cai,2 Jun Hou,2 Shuai Yi,2 Zhiping Lin1
CTC和attention机制是文本识别的两种主要方法
CTC测试时间短,但是正确率低。attention则相反
作者提出了一个高效的方法,叫做guided training of CTC(GTC),该方法用attention指导CTC学习一个更好的对其和特征表达
效果:鲁邦,准确 可以解决不规则文本识别问题,速度为attention方法的6倍。
从速度来看的话并不是简单的结合attention和CTC的,应该抛弃了逐步预测attention的方式。
Introduction
文字识别的挑战:different sizes, fonts, colors and character placements of scene texts
现在的文本识别框架,encoder-decoder结构+CTC/Attention。一些其他的方法使用矫正来预处理。
本文的动机:速度和准确率trade-off。(1) learning better feature representations from a more effective guidance, and (2) building correlations among the local features.

“attention-based methods make predictions depending on the features in previous time steps, this non-parallel decoding scheme will slow down the inference process a lot” 作者认为attention方法慢的主要原因是不并行,”where CTC loss misleads the training of its feature alignments and feature representations”,CTC效果不好的主要原因是CTC loss误导了特征对其和特征表达。

主要做法:使用矫正,训练时使用attention监督矫正模块,以得到更好的特征,使用GCN提取临近特征。
贡献:1.设计了GTC,是一个通用的提高CTC方法的方式,并且设计实验证明了。2.第一个在文本识别使用GCN。3.取得stoa性能并且速度快,能够识别规则和不规则文本。
可以看到其实这篇文章本质上是两条线,一个attention一个ctc,两条线直接没有任何的交叉。所以无法回避的一个问题就是他和其他既用ctc有用attention的方法有何不同。
这个思路其实和一篇ECCV很接近Using Object Information for Spotting Text,它是先标签A来训练前面的网络,然后冻住他用标签B来训练。等效于先用att训练,然后冻住stn和res来训练CTC
Related works
和Attention or STN+Attention以及STN+CTC的区别:guided training to optimize the CTC model,GCN
既用ctc有用attention的方法:
(Focusing attention: Cheng et al. 2017)直接组合ctc和attention效果不好。(CTC降低了特征表示的学习效率),利用guidance效果很好。
这个地方其实挺好的,自从Focusing attention说ctc+attention效果不好,还真没人研究这两方法的共存问题。
(Kim, Hori, and Watanabe 2017) used a shared encoder by CTC-attention and uses attention decoder for evaluation in speech recognition。encoder and rectification model in our network are solely optimized by the gradients calculated from the guidance。
感觉解释依旧牵强,不同是不同了,道理没说明白。
Method
为什么要guided:因为ctc有局限,作者认为As labels for CTC loss calculation are ambiguous, it is confusing to learning feature representations in each time step. Missing or superfluous characters may degrade the learning of its feature alignments and feature representations。作者利用相同编码器的ctc和att效果来说明这个问题。
主要网络结构:STN+ResNet+att guide+GCN CTC四部分。这里有个说法The STN, ResNet-CNN and the attentional guidance are solely trained with cross entropy loss, while the GCN+CTC decoder is trained with CTC loss.
看样子ctc的loss传到GCN就不再往回传了,不知道有没有相关的实验设计。后面看了一下并没有,不知道都回传是不是就变成了Focusing attention那样
STN,Res,Att都没什么好说的,用的都是标准的模型,和以前的工作一样,这里用的是GRU cell不是lstm cell。
GCN部分,也没什么好说的,用的就是Kipf的那个,和卷积本质上也没多大的区别。
| 这里分析一下GCN的输入和输出,”The input images are resized to have a fixed height of 64 pixels and a varying length, but not longer than 160 pixels.” 可以看到假设是64x160的原图,res的下采样为16x4,“‘1D’ denotes the attentional guidance described in the Methodology.”可以推测,它的STN输出大致是16xA的大小。$h_i$ 是一个向量,$c_i$是$h_i$的线性变换,邻接矩阵$A_S(i,j) = f(c_i,c_j)=\frac{c_i\cdot c_j}{ | c_i | c_j | }$计算的是两个节点的cos相似度。这里有个额外的不同是$A_D(i,j)=\frac{exp(-d_{ij}+\beta)}{exp(-d_{ij}+\beta)+1}$作者引入了一个位置向量来衡量两个特征之间的距离。$d_{ij}= | i-j | $其实就是考虑两个时刻的特征如果隔得太远就没啥参考的意义了。 |
这里的思想其实和上下文信息的论文很类似,有点受限注意力的意思,见图5。主要是考虑“We assume neighbouring time steps have supplementary features and there are certain correlations inside the feature sequence.”
有效是肯定有效的,有点像多了一层lstm,不过计算是卷积的计算量。算是蹭了一波GCN的热度吧

还有一点值得注意的是,“We also evaluated GTC by using another attentional guidance from (Li et al. 2019), which shows the robustness of GTC. The related experimental results are denoted by ‘2D’.”这个2D怎么和STN配合的,以及怎么和CTC配合的没有说。
Experiment
数据:We directly train our network using synthetic data (Synth90k, SynthText and SynthAdd) and the training images provided from public benchmarks (IIIT5K, SVT, IC03, IC13, IC15, COCO), which is the same as what is described in (Li et al. 2019)
第一个结论:Use Attention to Guide CTC (GTC)好于Use CTC to Guide Attention
这从另一个角度印证了我前面的看法,就是本质是两个独立的分支。至于谁帮助谁就看效果好了,不过我个人认为,作者的这种guidance无疑是最简单的那种,一个简单的道理,我STN+CTC效果不好,是因为我STN效果不好,那我用ATT来训练STN,后面接CTC加速,出来的结果就是这篇文章。当然马后炮谁都会放,我觉得ATT和CTC可以更深层次的融合,之前的Triple-Net就是一种尝试,而不是简单的我帮你训练一个模块的这种结合方式。
遗憾的是给出了Use Attention to Guide CTC (GTC) Use CTC to Guide Attention CTC的结果,而没有给出ATT的结果。没有办法证明他的强和数据的关系到底有多大。
第二个结论:Our GTC method outperforms CTC-based methods a lot while it maintains a fast inference
实验虽然给的很多但是基本没有说明,比如baseline有没有STN,2D的STN到底怎么实现的,为什么加了STN效果没有SAR好,以及与后面的GCN又是怎么配合的。为什么2D ATT的效果不如1D。

此外“The result in Table 3 shows that CTC is not an effective guidance compared with Attention. The result also indicates that the CTC loss harms the training process and produces poor feature representations.“
“Besides, we find that GTC also has better transformation results compared with STN+CTC framework (see Figure 4).“
个人觉得后面句话才是性能增长的主要的点,什么guidance都是虚无缥缈的
总的来说
这篇文章虽然毒点很多,不过有很多值得称赞的地方,首先是他敢于突破“Focusing attention”的结论,我一直觉得两个方法融合是肯定会有人做的,这是很多领域共同的经验。然后就是它对这个loss不回传的设计,估计是吃了苦头的,不过他没有写都回传的效果让人难以理解。最后就是蹭了一波GCN的热度,虽然本质就是引入了领域的信息,但是瞬间论文看起来就高大上了一些。
文本检测识别的几个趋势
趋势1:不管我训练复杂不复杂,测试简单就可以了,可以加速,常见的套路,训练加个额外监督,反正可以学好,测试不用就完了。
趋势2:数据越用越多,反正数据多效果就好,评委也不会看出来我数据用的比别人多。
趋势3:一条路走不通时,方法融合才是硬道理,简单又高效,比如spcnet,比如htc,比如这篇
MIRROR-GENERATIVE NEURAL MACHINE TRANSLATION
Global Context-Aware Progressive Aggregation Network for Salient Object Detection(AAAI oral 已开源)
作者:Zuyao Chen, Qianqian Xu, Runmin Cong, Qingming Huang
机构:University of Chinese Academy of Sciences, Beijing, China
深度卷积神经网络对显著目标检测的有效体现在特征提取上
以往的工作大多采用多层特征集成,忽略了不同特征之间的差异。此外,高层特征在自上而下的路径上传递过程中也存在稀释过程。
为了解决这些问题,我们提出了一种新的网络,称为GCPANet,通过一些渐进的上下文感知功能交织聚合(FIA)模块,有效地集成低层外观特征、高层语义特征和全局上下文特征,并以监督的方式生成显著性映射。此外,头注意(HA)模块通过利用空间和通道的注意力来减少信息冗余和增强顶层特征,并利用自细化(SR)模块进一步细化和增强输入特征。此外,我们设计了全局上下文流(Global Context Flow, GCF)模块来生成不同阶段的全局上下文信息,旨在了解不同突出区域之间的关系,缓解高层特征的稀释效应。在6个基准数据集上的实验结果表明,该方法在定量和定性上都优于现有的方法。
这篇文章主要做 salient object detection, 主要的模式是分割,主要的思路是进一步加强特征提取和特征融合,估计是在FCN上面增加了一些模块来提升效果
作者提到了FIA HA SR GCF等模块来达到上面的目的,HA看起来像是Transformer里面的东西
SOD含义:Salient object detection models usually aim to detect only the most salient objects in a scene and segment the whole extent of those objects.
一般认为,良好的显著性检测模型应至少满足以下三个标准:
1)良好的检测:丢失实际显著区域的可能性以及将背景错误地标记为显著区域应该是低的;
2)高分辨率:显著图应该具有高分辨率或全分辨率以准确定位突出物体并保留原始图像信息;
3)计算效率:作为其他复杂过程的前端,这些模型应该快速检测显著区域。
Introduction
深度学习的发展对显著目标检测有很大的促进左右。FCN为代表的的工作充分的利用了目标的特征。一个结论,一般来说,高阶特征有利于突出物体的粗定位,而包含空间结构细节的低阶特征则有利于细化边界。然而基于FCN的方法也存在问题:由于不同层次特征之间的差异,语义信息与外观信息的简单结合不够,缺少考虑不同特征对突出目标检测的不同贡献;以往的研究大多忽略了全局语境信息,有利于推导出多个突出区域之间的关系,产生更完整的显著性结果。
GCPANet主要包含四个模块:Feature Interweaved Aggregation (FIA) module, Self Refinement (SR) module, Head Attention (HA) module, and Global Context Flow (GCF) module. 具体的顺序如下:HA backbone FIA SR GCF
主要贡献:1.提出了4各模块 2.GCF生成全局上下文信息,FIA融合所有的特征。3.效果好
作者提出了FCN的两个主要问题:特征融合不好(FIA,HA,SR),忽略了全局信息(GCF)。很明显在目标检测连这两个问题已经研究了很久,不知道在显著目标检测里面是怎样的一个说法
Related Work
(Zhao et al. 2015)集成了局部和全局的特征(FCN based)。
(Wang et al. 2016)采用递归CNN逐步细化预测显著性图。
(Hou et al. 2017)在skip layer结构中引入了短连接来捕捉细节。
(Zhanget al. 2017)将基于多分辨率的多层特征图级联起来,提出了一种边界细化策略。
……
最近,(Wu, Su, and Huang 2019)提出了一种利用注意力机制提炼高层次特征的级联部分解码器
(Qin et al. 2019)提出了一种边界感知模型,用于分割突出的目标区域并同时预测边界。
(Liu et al. 2019)对FPN结构进行了扩展,加入了金字塔池模块,融合了粗层次语义特征和细层次特征。
可以看到,早从15年开始,显著目标检测就有人开始关注,全局特征和局部特征的提炼,以及高效特征融合的方式,很遗憾的是作者这里并没有说他的方法和其他人的区别在哪里,这让我小小的心里充满了大大的疑惑。
从这些研究里面我们可以看到,特征融合不仅仅在目标检测领域,就算是他的子任务都是经久不衰,值得我们反复发论文的好点子。
Methodology

该网络是一种对称的编码器-解码器结构,其中编码器组件以ResNet-50为基础提取多级特征,解码器组件以监督的方式逐步集成多级综合特征生成显著性映射。具体来说,我们首先使用了一个HA模块来增强对突出物体具有高响应的空间区域和特征通道,以及一个SR模块来通过特征细化和增强来生成第一阶段的高级特征。然后,我们逐步级联一个FIA模块和一个SR模块在三次,以学习更多的区别特征和生成更准确的显著性地图。在FIA模块中,低层细节信息、高层语义信息和全局上下文信息以交织的方式融合在一起。每个FIA模块后续的SR模块是细化粗聚集特征。需要注意的是,全局上下文信息是由提出的GCF模块产生的,它捕获了不同显著区域之间的关系,并约束了更完整的显著性预测。为了便于优化,我们将各子级的支路辅助损失与主导损失相结合。
可以看到,该工作仍然是一个FCN的变种,除开前面提到的四个模块和FCN完全一样。
FIA用来融合多层的特征
GCF用于处理最高层的特征
SR用于增强每一层的特征






MIRROR-GENERATIVE NEURAL MACHINE TRANSLATION
MIRROR-GENERATIVE NEURAL MACHINE TRANSLATION(ICLR 满分论文)
Zaixiang Zheng, Hao Zhou, Shujian Huang, Lei Li, Xin-Yu Dai, Jiajun Chen
机构:南京大学,字节跳动
Introduction
背景知识:
平行/对应语料库(parallel corpora)是由原文文本及其平行对应的译语文本构成的双语/多语语料库,其对齐程度可有词级、句级、段级和篇级几种。平行语料库按翻译方向的不同有单向平行语料库(uni-directional parallel corpora)、双向平行语料库(bi-directional parallel corpora) 和多向平行语料库(multidirectional parallel corpora)等三种形式。
对比/类比语料库(comparable corpora)是由不同语言的文本或同一种语言不同变体的文本所构成的两个或两个以上的语料库。 类比语料库也可再细分出单语类比库和双语/多语类比库。前者收集一种语言类似环境下的类似内容的文本,如Loviosa构建的ECC(English Comparable Corpus, TEC的姊妹项目)属于此种。而后者收集的是在内容、语域、交际环境等方面相近的不同语言文本,多用于对比语言学
动机:
常规的神经机器翻译(NMT)需要大量平行语料,而平行预料难以获得。原始的非平行语料极易获得,但是现有基于非平行语料的方法仍旧有提升的空间。
为此,本文提出一种镜像生成式机器翻译模型:MGNMT(mirror-generative NMT)。该框架同时集成了source-target和target-source的翻译模型及其各自语种的语言模型。MGNMT中的翻译模型和语言模型共享隐语义空间,所以能够从非平行语料中更有效地学习两个方向上的翻译。此外,翻译模型和语言模型还能够联合解码,提升翻译质量。
如何共享语义?
如何联合解码?
现有方法的问题:
当下的NMT系统在研究非平行语料时,一般是用回译法(back-translation )。”back-translation individually updates the two directions of machine translation models”,这显得不够高效。”Namely, each updating of $T_{My\rightarrow x}$ will not directly benefit $T_{Mx\rightarrow y}$.” $T_M$这里指的是src2tgt translation model。对此,有学者提出联合回译法和对偶学习(dual learning),在迭代训练中使二者隐含地相互受益。”But translation models in these approaches are still independent.”。理想状态下,当两个方向的翻译模型相关,则非平行语料所带来的增益能够进一步提高。此时,一方每一步的更新都能够提升另一方的性能,反之亦然。这将更大地发挥非平行语料的效用。
什么是back-translation:有了目标语言句子y, 用训练好的目标语言到源语言的翻译模型得到伪句对(x’, y), 加入到平行句对中一起训练.
对于解码,有学者提出在翻译模型$T_{Mx\rightarrow y}$ 中直接插入独自在target语种上训练的外部语言模型$L_{My}$。有效但是作者认为不够好:$L_{My}$来自于外部,独立,无法良好协作,甚至带来冲突;$L_{My}$仅在解码中使用,而训练过程没有。这导致训练和解码不一致,可能会影响性能。
总的来说作者就之前的方法找了两个比较不足的点:back-translation两个翻译器没有直接的交互,解码过程的语言模型不可训练提出了新的结局思路。感觉两个方法其实都有很大的借鉴意义。
第一:Cycle GAN,包括这篇其实是为了解决不同域之间数据缺乏现象的一类代表,现在我们面临越来越多这种问题,包括文字最近的GA-DAN其实也是这个思路。如何有效的在循环,或者这种对称模式加加入更多更有效的交互对于我们值得思考。
第二:直接插入语言模型现在可太常见了,以zeroshot为代表的很多无监督方法,都直接引入语言模型。很明显这些语言模型能否混合训练对于我们cv届其实是一个更难得问题,视觉特征不应该直接对其语义特征,而是我们应该联合训练两个模型。
贡献:
本文提出镜像生成式NMT(MGNMT)尝试解决上述问题,进而更高效地利用非平行语料。MGNMT在一个统一的框架中联合翻译模型(两个方向)和语言模型(两个语种)。受生成式NMT(GNMT)的启发,MGNMT中引入一个在x和y之间共享的隐语义变量z。本文利用对称性或者说镜像性质来分解条件联合概率p(x, y | z): MGNMT的概率图模型如Figure 1所示:
图一说明了有p(x z),p(y z),p(x y),p(y x),z是一个隐变量

通过共享的隐语义变量将两个语种的双向翻译模型和语言模型分别对齐,如Figure 2所示:
引入隐变量后,将各个模型关联起来,且在给定z下条件独立。如此的MGNMT有如下2个优势:
(1)训练时,由于隐变量的作用,两个方向的翻译模型不再各自独立,而是相互关联。因此一个方向上的更新直接有益于另一个方向的翻译模型。这提升了非平行语料的利用效率;
(2)解码时,MGNMT能够天然地利用其内部target端的语言模型。这个语言模型是与翻译模型联合学习的,联合语言模型和翻译模型有助于获得更好的生成结果。
看了图二,一脸懵逼,唯一个感觉是真的像Cycle GAN那种类型的图。隐变量z在这里起了至关重要的作用,从公式和图2都能反映出来,也顺便回答了我们上面提出的两个问题。那么z到底是如何工作的呢?
BACKGROUND AND RELATED WORK
| 神经机器翻译:传统的NMT通常是用encoder-decoder来进行判别式学习,学习目标是$logp(y | x;\theta_{xy})$ |
近些年,有方法提出了语言xy之间存在共享的语义z,它被NMT隐式的学习。GNMT则用联合概率(生成模型)来代替判别模型。
上面这两种方法都是平行语料的,对于非平行预料,back-translation和对偶学习是常见的方法,不过效果没有MGNMT好
一些其他的方法通过贡献参数和词汇表来处理非平行语料,不过无法处理差异大的语言对(中英)
和GNMT区别:尽管GNMT包含一个源端语言模型,但它不能帮助解码。相比之下,MGNMT很可能会联合学习翻译和语言建模,并且可以自然地将两者结合在一起以获得更好的一代。
可以看到,该工作室GNMT的一个改进,主要的区别在于针对非平行语料镜像结构,以及联合学习的语言模型,也正是上面提到的两点,对于其他的方法,作者没有给出太多理论上的分析,主要是靠实验来说明的。
MIRROR-GENERATIVE NEURAL MACHINE TRANSLATION

MGNMT的整体框架如Figure 3所示:
MGNMT对双语句对进行联合建模,具体是利用联合概率的镜像性质: 其中隐变量z(本文选用标准高斯分布)表示x和y之间的语义共享。隐变量桥接了两个方向的翻译模型和语言模型。下面分别介绍平行语料和非平行语料的训练及其解码。
这个图的解释很少,基本上只给出了一个简单的公式以及对z的说明。公式的推导见公式1,可以看到,隐变量z在这里是桥梁,右边是我们希望优化的模型与z的关系,左边是我们对z的求解过程?
平行语料的训练
给定平行语料对(x,y),使用随机梯度变分贝叶斯法(stochastic gradient variational Bayes,SGVB)得到$log p(x,y)$的近似最大似然估计。近似后验可以参数化为: 从方程(1)中可以得出联合概率对数似然的证据下界(Evidence Lower BOund,ELBO): 方程(2)中第一项表示句子对log似然的期望,该期望用蒙特卡洛采样获得。第二项是隐变量的近似后验和先验分布之间的KL散度。通过重新参数化的技巧,使用基于梯度的算法联合训练所有部分。
这里是一个近似优化的思想,首先将隐变量z近似成一个高斯,然后利用KL散度来衡量两个概率分布之间的差异。由于z的近似,所以极大似然估计和真实分布之间的差距就是一个KL散度$\log p(x, y) = \mathcal{L}(x, y ; \boldsymbol{\theta}, \phi)+D_{\mathrm{KL}}[q(z x, y ; \phi) | p(z)] $,估计这么写就高端大气一点吧。
非平行语料的训练
本文在MGNMT中设计一种迭代训练方法以利用非平行语料。在该训练过程中两个方向的翻译都能够受益于各自的单语种数据集,且能够相互促进。非平行语料上的训练方法如 Algorithm 1所示:

其中(x,y)表示source-target语言对,θ表示模型参数,$D_{xy} $表示平行语料,$D_x$和$D_y$分别表示各自的非平行单语语料。
给定两个非平行句子:source语种中的句子$x^s$和target语种中的句子$y^t$。目标是使它们的边际分布似然的下界相互最大化: 其中小于等于号右边的两项分别表示source和target的边际对数似然的下界。
| 以上述第二项为例。用$p(x | y^t)$在source语种中采样出的x作为$y^t$的翻译结果(即回译)。如此可以获得伪平行句子对$(x, y^t)$。在方程(4)中直接给出该项的表达式: |

同理可以得到另一项的表达式:

根据上述两个公式可以得到2个方向的伪平行语料,再将二者联合起来训练MGNMT。方程(3)可以用基于梯度的方法进行更新,计算如方程(6)所示:

| 上述利用非平行语料的整个训练过程在某种程度上与联合回译相似。但是联合回译每次迭代只利用非平行语料的一个方向来更新一个方向的翻译模型。由于隐变量来自于共享近似后验q(z | x, y;Φ),所以可充当促进MGNMT中两个方向单语种性能的桥梁。 |
可以看到,这一顿操作让人眼花缭乱,公式上的推导说明了作者设计的思路,很难理解他是怎么想过去的,不过我们带着结果反过来看就比较容易理解了。从back-translation出发,我们很容易得到结论:$y^t$回译得到$x_{pseu}$ ,我们的目标使用<$x_{pseu}$,$y^t$>来优化$T_{Mx\rightarrow y }$,然而这里不简单的是引入了隐变量z,那么同时我们还要根据<x,y>来近似后验概率q(z x, y;Φ)
解码
| MGNMT在解码中同时对翻译模型和语言模型建模,所以在解码时能够获得更流畅更高质量的翻译结果。给定句子x(或者target句子y),通过y=argmax_{y} p(y | x)=argmax_{y} p(x, y)找到相应的翻译结果。具体的解码流程如 Algorithm 2所示: |

以srg2tgt翻译模型为例。对给定的source句子x做如下操作:
| (1)从标准高斯先验分布中采样一个初始化的隐变量z,然后得到一个初始翻译y~=arg max_y p(y | x, z); |
| (2)从后验近似分布q(z | x, y~; Φ)不断采样隐变量,用beam search重解码以最大化ELBO。从而迭代生成y~: |
每个步骤的解码得分由x->y翻译模型和y的语言模型决定,这有助于翻译结果更像target语种。重建的重排得分由y->x和x的语言模型决定。重排是指翻译后对候选的重新排序。在重排中引入重建得分确实有助于翻译效果的提升。
Paper_reading
1 | |
Paper_reading
1 | |